从零开始的CUDA学习之旅
本文的主要基座为这些项目:(摘抄+一些简单自己的理解),
非常感谢文章作者们的倾情教授得以踏入一探CUDA究竟,学生朽木。
https://github.com/Tony-Tan/CUDA_Freshman/tree/master
https://face2ai.com/program-blog/
注:如果使用clion编写程序,需要自行在工具链设定中指定nvcc的变量地址和GPU的计算架构能力(比如3060的计算里是85),否则找不到GPU框架
本文不会记录具体的代码,具体代码参考原项目的代码库,除非在此外有必要的代码会出现在文中。
启、基础概念解析
在CUDA学习中,我们很容易遇到一些容易混淆的概念,这里先作解释,可跳过不懂的时候翻阅即可(感谢文章 https://zhuanlan.zhihu.com/p/266633373):
硬件架构:SM,��线程束, SP,Warp调度
SM
GPU中每个SM都能支持数百个线程并发执行,每个GPU通常有多个SM,当一个核函数的网格被启动的时候,多个block会被同时分配给可用的SM上执行。
注意: 当一个blcok被分配给一个SM后,他就只能在这个SM上执行了,不可能重新分配到其他SM上了,多个块可以被分配到同一个SM上。
在SM上同一个块内的多个线程进行线程级别并行,而同一线程内,指令利用指令级并行将单个线程处理成流水线。
线程束
线程束单位32,表示一个SM在同一时间内执行的最多线程
CUDA 采用单指令多线程SIMT架构管理执行线程,不同设备有不同的线程束大小,但是到目前为止基本所有设备都是维持在32,也就是说每个SM上有多个block,一个block有多个线程(可以是几百个,但不会超过某个最大值),但是从机器的角度,在某时刻T,SM上只执行一个线程束,也就是32个线程在同时同步执行,线程束中的每个线程执行同一条指令,包括有分支的部分.一个SM上在某一个时刻,有32个线程在执行同一条指令,这32个线程可以选择性执行,虽然有些可以不执行,但是他也不能执行别的指令,需要另外需要执行这条指令的线程执行完,然后再继续下一条 同一�个SM上可以有不止一个常驻的线程束,有些在执行,有些在等待,他们之间状态的转换是不需要开销的
软件架构:Kernel,Grid,Block
CUDA核函数会被GPU上的多个线程执行。我们可以通过如下方式来定义一个kernel:
func_name<<<grid, block>>>(param1, param2, param3....);
这里的grid与block是CUDA的线程组织方式,具体如下图所示:

**Grid:**单独kernel启动的所有线程组成一个grid,grid中所有线程共享global memory。Grid包含很多Block,可以是一维二维或三维。
**Block:**block由�许多线程组成,同样可以有一维、二维或者三维。
block内部的多个线程可以同步(synchronize),可访问共享内存(share memory)。
CUDA中可以创建的网格数量Grid跟GPU的计算能力有关,可创建的Grid、Block和Thread的最大数量如下所示:

所有CUDA kernel的启动都是异步的,当CUDA kernel被调用时,控制权会立即返回给CPU。在分配Grid、Block大小时,我们可以遵循这几点原则:
-
保证block中thread数目是32的倍数。这是因为同一个block必须在一个SM内,而SM的Warp调度是32个线程一组进行的。
-
避免block太小:每个blcok最少128或256个thread。
-
根据kernel需要的资源调整block,多做实验来挖掘最佳配置。
-
保证block的数目远大于SM的数目。
CUDA中每一个线程都有一个唯一的标识ID即threadIdx,这个ID随着Grid和Block的划分方式的不同而变化,例如:
// 一维的block,一维的thread
int tid = threadIdx.x + blockIdx.x * blockDim.x;

那么具体的核函数是怎么和计算线程挂勾上的呢?我们接着看:
核函数只能在主机端调用,调用时必须申明执行参数。调用形式如下:
Kernel<<<Dg,Db, Ns, S>>>(paramlist);
• <<< >>>内是核函数的执行参数,告诉编译器运行时如何启动核函数,用于说明内核函数中的线程数量,以及线程是
如何组织的。
• 参数Dg用于定义整个grid的维度和尺寸,即有多少个block, 为dim3类型
Dim3 Dg(Dg.x, Dg.y, 1)表示grid中每行有Dg.x个block,每列有Dg.y个block,第三维一般为1.
(目前一个核函数对应一个grid), 这样整个grid中共有Dg.x*Dg.y个block。
• 参数Db用于定义一个block的维度和尺寸,即有多少个thread,为dim3类型。
Dim3 Db(Db.x, Db.y, Db.z)表示整个block中每行有Db.x个thread,每列有Db.y个thread,高度为Db.z。
Db.x 和 Db.y最大值为1024,Db.z最大值为64。一个block中共有Db.x*Db.y*Db.z个thread。
• 参数Ns是一个可选参数,用于设置每个block除了静态分配的shared Memory以外,最多能动态分配的shared memory
大小,单位为byte。不需要动态分配时该值为0或省略不写。
• 参数S是一个cudaStream_t类型的可选参数,初始值为零,表示该核函数处在哪个流之中。
我们用核�函数执行参数规定计算资源,然后当我们执行一个kernel函数时,cuda自动帮我们赋值对应需要的x,y去满足对应规则。相当于我们规定有多少人需要干活,然后在里面可以自己选择不同维度和排布作为分配的个数i然后让他们干活就好。
接下来我们看看如何确定需要多少block和thread:
(如何确定最优可以看https://blog.csdn.net/Kelvin_Yan/article/details/53589411)
先获取线程数目:(参考https://blog.csdn.net/weixin_42034217/article/details/113784032)
int getThreadNum()
{
cudaDeviceProp prop;
int count;
HANDLE_ERROR(cudaGetDeviceCount(&count));
printf("gpu num %d\n", count);
HANDLE_ERROR(cudaGetDeviceProperties(&prop, 0));
printf("max thread num: %d\n", prop.maxThreadsPerBlock);
printf("max grid dimensions: %d, %d, %d)\n",
prop.maxGridSize[0], prop.maxGridSize[1], prop.maxGridSize[2]);
return prop.maxThreadsPerBlock;
}
例如有一个 1920×1080的一维矩阵,应该如何设计blockNum和ThreadNum ?
int threadNum = getThreadNum();
int blockNum = (width * height - 0.5) / threadNum + 1;
机器block数量非常多,用1维就够了,ThreadNum用机器最大的线程1024即可,那么blockNum就等于总数除以每个block的线程数,为什么要 -0.5和+1是为了防止整除、进一位等,总之加上为好
conv<<<blockNum, threadNum>> >
(imgGpu, kernelGpu, resultGpu, width, height, kernelSize);
__global__ void conv(float *img, float *kernel, float *result,
int width, int height, int kernelSize)
{
int ti = threadIdx.x;
int bi = blockIdx.x;
int id = (bi * blockDim.x + ti);
if(id >= width * height)
{
return;
}
int row = id / width;
int col = id % width;
for(int i = 0; i < kernelSize; ++i)
{
for(int j = 0; j < kernelSize; ++j)
{
float imgValue = 0;
int curRow = row - kernelSize / 2 + i;
int curCol = col - kernelSize / 2 + j;
if(curRow < 0 || curCol < 0 || curRow >= height || curCol >= width)
{}
else
{
imgValue = img[curRow * width + curCol];
}
result[id] += kernel[i * kernelSize + j] * imgValue;
}
}
}
对于block 和线程的索引,其实有15种索引方式,可参考https://blog.csdn.net/aliexken/article/details/105290119
https://blog.csdn.net/TH_NUM/article/details/82983282
CUDA Context
CUDA Stream
Hyper-Q,Multi Stream,MPS
为什么CUDA API 都是**指针
因为在cuda上,GPU提前没有分配地址,所以说只能靠 (void **)(&dev_c)方式来定位到要分配内存的地方。
简单说,(void**)(地址)以后,就是一个指向指针类型的指针。这有这样,才能让指针在子函数中获得目标地址,不然改的就是形参的指向,没有意义。比如你传入一个NULL的指针地址,改变内容了又能怎样。
cudaMalloc的第一个参数传递的是存储在cpu内存中的指针变量的地址(只声明好了地址给他准备用),cudaMalloc在执行完成后,向这个地址中写入了一个地址值(此地址值是GPU显存里的)这样我们才能把host的内存拷贝到显存的位置上。
直接传值,函数对形参值的修改无法传出,因为形参的是在栈上创建的,函数结束后生命周期就结束了,所以想将修改的值传出来,就要��传入要修改值的指针
在我们是想得到函数cudaMalloc在device上申请的内存,既然要把申请的内存地址返回给一个指针,那就用二重指针解决,这样既解决了CUDA函数返回类型的统一,也解决了申请的内存地址返回给一个指针问题
DIVUP
在CUDA计算线程管理中,很重要的一点是DIVUP,因为计算机除法通常情况是向下取整,为了能够满足正常计算需求,我们需要在结果上进行加一,同时要用-1容纳正常整除的情况,计算就变成了(a-1)/b + 1
一、入门CUDA
什么是CUDA
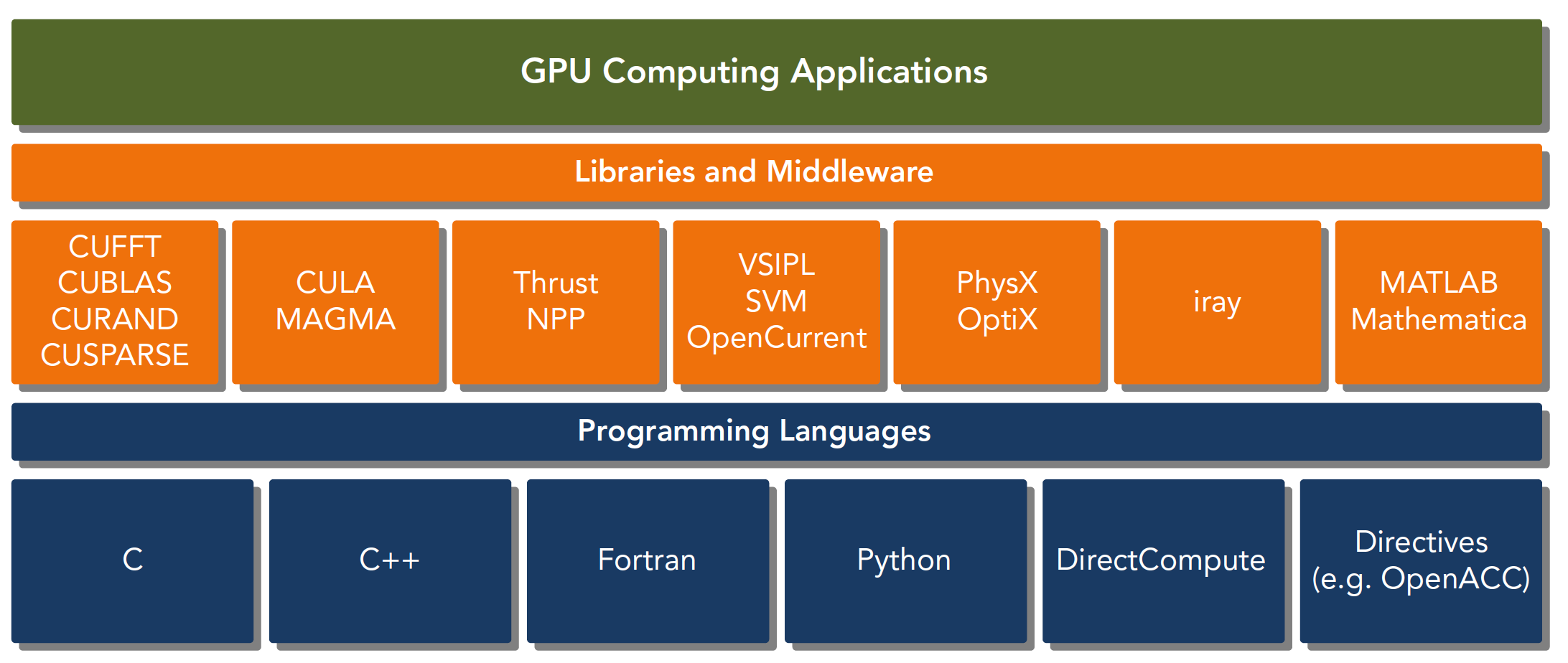
CUDA C 是标准ANSI C语言的扩展,扩展出一些语法和关键字来编写设备端代码。
而且CUDA库本身提供了大量API来操作设备完成计算。
对于API也有两种不同的层次,一种相对交高层,一种相对底层。
-
CUDA驱动API
-
CUDA运行时API
驱动API是低级的API,使用相对困难,运行时API是高级API使用简单,其实现基于驱动API。 这两种API是互斥的,也就是你只能用一个,两者之间的函数不可以混合调用,只能用其中的一个库。
一个CUDA应用通常可以分解为两部分,
-
CPU 主机端代码
-
GPU 设备端代码
CUDA nvcc编译器会自动分离你代码里面的不同部分,用C写的使用本地的C语言编译器编译;设备端核函数代码通过nvcc编译,链接阶段,在内核程序调用或者明显的GPU设备操作时,添加运行时库。
nvcc 是从LLVM开源编译系统为基础开发的。

CUDA抽象了硬件实现:
-
线程组的层次结构
-
内存的层次结构
-
障碍同步
这些都是我们后面要研究的,线程,内存是主要研究的对象,我们能用到的工具相当丰富,NVIDIA为我们提供了:
-
Nvidia Nsight compute集成开发环境
-
CUDA-GDB 命令行调试器
-
性能分析可视化工具
-
CUDA-MEMCHECK工具
-
GPU设备管理工具
一般CUDA程序分成下面这些步骤:
-
分配GPU内存
-
拷贝内存到设备
-
调用CUDA内核函数来执行计算
-
把计算完成数据拷贝回主机端
-
内存销毁
一个完整的CUDA应用可能的执行顺序如下图:
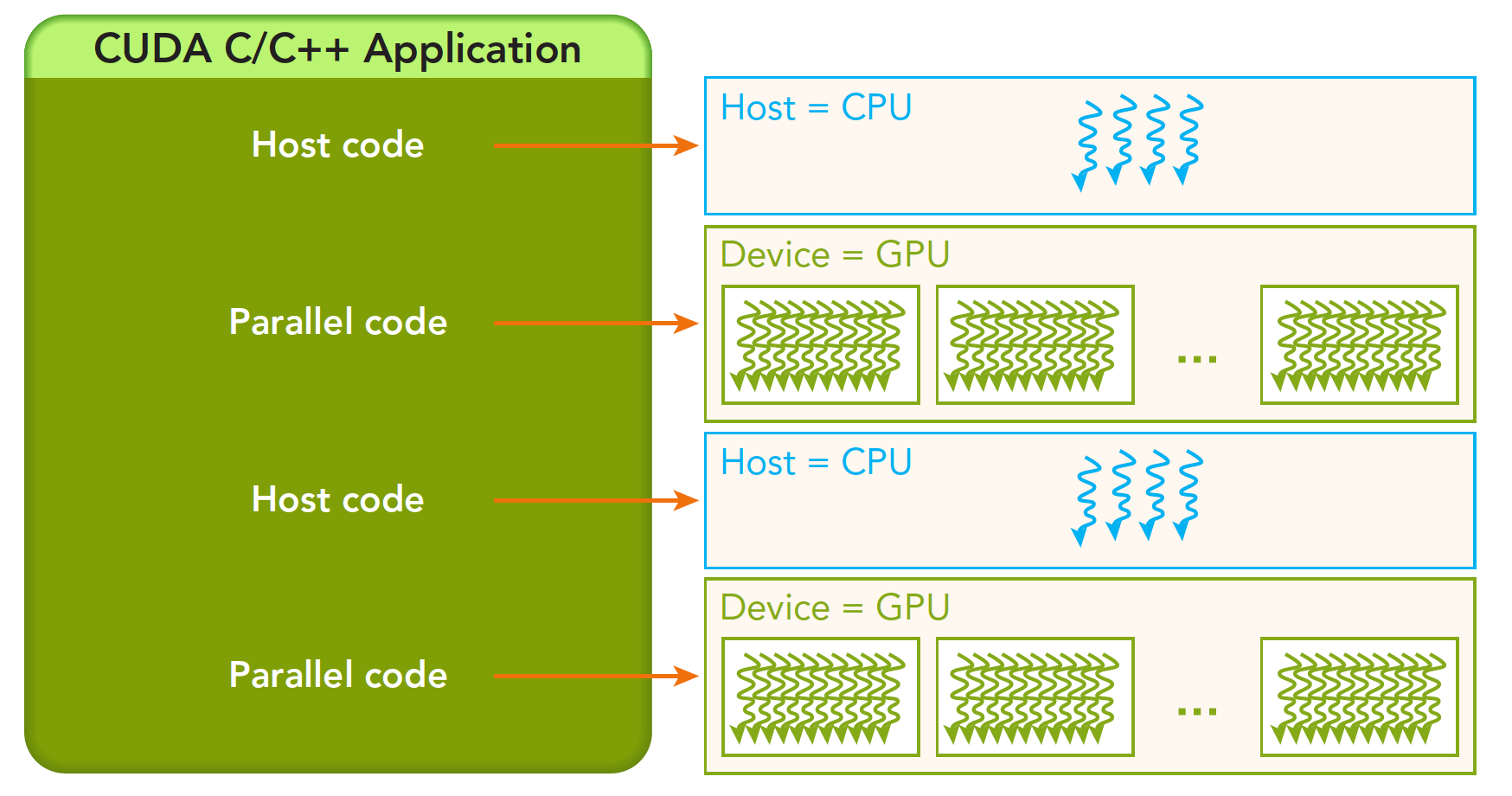
从host的串行到调用核函数(核函数被调用后控制马上归还主机线程,也就是在第一个并行代码执行时,很有可能第二段host代码已经开始同步执行了)。
需要注意的是CUDA API基本都是返��回一个error状态,并不是返回一个指针结果之类的
要掌握哪些内容
从宏观上我们可以从以下几个环节完成CUDA应用开发:
-
领域层
-
逻辑层
-
硬件层
第一步就是在领域层(也就是你所要解决问题的条件)分析数据和函数,以便在并行运行环境中能正确,高效地解决问题。 当分析设计完程序就进入了编程阶段,我们关注点应转向如何组织并发进程,这个阶段要从逻辑层面思考。 CUDA模型主要的一个功能就是线程层结构抽象的概念,以允许控制线程行为。这个抽象为并行变成提供了良好的可扩展性(这个扩展性后面有提到,就是一个CUDA程序可以在不同的GPU机器上运行,即使计算能力不同)。 在硬件层上,通过理解线程如何映射到机器上,能充分帮助我们提高性能。
GPU中大致可以分为几个关键部分。
-
核函数
-
内存管理
-
线程管理
-
流
以上这些理论同时也适用于其他非CPU+GPU异构的组合。 下面我们会说两个我们GPU架构下特有几个功能,对内存和线程的控制:
-
通过组织层次结构在GPU上组织线程的方法
-
通过组织层次结构在GPU上组织内存的方法
内存管理入门

接下来通过简单的加法程序理解CUDA中的内存管理编程模型
cudaError_t cudaMemcpy(void * dst,const void * src,size_t count,
cudaMemcpyKind kind)
这个函数是内存拷贝过程,可以完成以下几种过程(cudaMemcpyKind kind)
-
cudaMemcpyHostToHost
-
cudaMemcpyHostToDevice
-
cudaMemcpyDeviceToHost
-
cudaMemcpyDeviceToDevice
如果函数执行成功,则会返回 cudaSuccess 否则返回 cudaErrorMemoryAllocation,具体的错误信息可以用下列API获取
char* cudaGetErrorString(cudaError_t error)
线程管理入门
一个线程块block中的线程可以完成下述协作:
-
同步
-
共享内存
我们需要眼熟这些东西:块的坐标(blockIdx.x等),网格的大小(gridDim.x 等),线程编号(threadIdx.x等),线程的大小(tblockDim.x等
依靠下面两个内置结构体可确定线程标号:blockIdx(线程块在线程网格内的位置索引)threadIdx(线程在线程块内的位置索引)
注意这里的Idx是index的缩写,这两个内置结构体 blockIdx threadIdx 基于 uint3 定义,包含三个无符号整数的结构,通过三个字段来指定z:
-
blockIdx.x
-
blockIdx.y
-
blockIdx.z
上面这两个是坐标,我们要有同样对应的两个结构体 blockDim gridDim 来保存其范围,也就是blockIdx中三个字段的范围threadIdx中三个字段的范围:
他们是dim3类型(基于uint3定义的数据结构)的变量,也包含三个字段x,y,z.
-
blockDim.x
-
blockDim.y
-
blockDim.z
具体的初始化过程类似 dim3 block(4,2); dim3 grid(2,2); 然后传入核函数
网格和块的维度一般是二维和三维的,也就是说一个网格通常被分成二维的块,而每个块常被分成三维的线程。 注意:**dim3是手工定义的,主机端可见。uint3是设备端在执行的时候可见的,不可以在核函数运行时修改,初始化完成后uint3值就不变了。**他们是有区别的!这一点必须要注意。
不同组织对效率的影响
grid 和block的分别有多种组织方式:
-
二维网格二维线程块
-
一维网格一维线程块
-
二维网格一维线程块
这张图可以方便你了解线程的分布模型(简单来看就是对应的x,y的block位置+线程偏移量,其中索引根据block的位置和大小确定基准位置(ix,iy)是整个线程模型中任意一个线程的索引,或者叫做全局地址,局部地址是(threadIdx.x,threadIdx.y),只能索引线程块内的线程,这里的nx和ny是我想分配的最大范围(相当于一个局部的上限,所以你要找到当前的位置必须+ iy*nx)线性位置的计算方法是:idx=ix+iy∗nx

如果每个不同的线程执行同样的代码,又处理同一组数据,将会得到多个相同的结果,显然这是没意义的,为了让不同线程处理不同的数据,CUDA常用的做法是让不同的线程对应不同的数据,也就是用线程的全局标号对应不同组的数据
设备内存或者主机内存都是线性存在的,比如一个二维矩阵 (8×6),存储在内存中是这样的:

我们要做管理的就是:
-
线程和块索引(来计算线程的全局索引)
-
矩阵中给定点的坐标(ix,iy)
-
(ix,iy)对应的线性内存的位置
我们可以用线程的全局坐标对应矩阵的坐标,线程的坐标(ix,iy)对应矩阵中(ix,iy)的元素,这样就形成了一一对应,用不同的线程处理矩阵中不同的数据.例如用ix=10,iy=10的线程去处理矩阵中(10,10)的数据,当然你也可以设计别的对应模式,但是这种方法是最简单出错可能最低的。
具体的分配过程看代码,但大抵遵循:(分配固定,执行乱序:执行按照warp走,一次32个thread,全局内存的index可能被分到两个warp里)
首先决定一个block需要分布的最大x y z 范围;接下来固定block的具体分布,需要小于nx,ny,nz;然后根据固定好的nx,ny,nz去做向上取整除block.x,y,z得到具体的grid坐标数值,然后分配给核函数就好【记得外面分配了什么维度里面就拿什么维度去操作,目的都是拿到全局抽象坐标】
我要做的就是给他一个全局资源,然后在里面得到具体的全局索引 idx,注意到这个位置是可以加偏移量的,你只需要让和函数的指定线程(比如某个block内的线程)帮你干指定的活就可以了,在那干活不重要可以有你决定.
有时候对于数组要防止溢出,你可以只在小于最大大小的区域进行for遍历的干活,这样就可以只利用正常的线程干活得到结果了,如: 【线程索引小于最大边界的干活,否则会溢出,要用抽象全局索引进行计算!】一旦进入核函数,所有线程都会执行函数体的相同功能,所以关键是你要用那么多人去做什么事(你可以让他们对数组都进行整体相同操作(矩阵相加),也可以让他们每个人做一个相同操作但只有一个结果(每个人都把数字和某个全局结果相加
需要注意,这个操作要保证乱序不冲突

你也可以这么写:

接下来开始计算

从结果看到:
-
改变执行配置(线程组织)能得到不同的性能
-
传统的核函数可能不能得到最好的效果
-
一个给定的核函数,通过调整网格和线程块大小可以得到更好的效果
核函数及错误处理
核函数代码在设备上运行,用NVCC编译,产生的机器码是GPU的机器码,所以我们写CUDA程序就是写核函数,第一步我们要确保核函数能正确的运行,第二优化CUDA程序的部分:算法、内存结构、线程结构。
通过指定grid和block的维度,�我们可以配置内核中线程的数目,内核中使用的线程布局
我们可以使用dim3类型的grid维度和block维度配置内核(有多少block和thread),也可以使用int类型的变量,或者常量直接初始化:
func_name<<<grid, block>>>(param1, param2, param3....);
kernel_name<<<4,8>>>(argument list);

__global__ void kernel_name(argument) //其实就是传统函数前面加了核函数标识符
{
printf("GPU: Hello world!\n");
}
//1个块
kernel_name<<<1,32>>>(argument list); //其实就是传统函数调用中间加了<<>>管理
//32个块
kernel_name<<<32,1>>>(argument list);
当主机启动了核函数,控制权马上回到主机
想要主机等待设备端执行可以用下面这个指令:
cudaError_t cudaDeviceSynchronize(void);
//这是一个显示的方法,对应的也有隐式方法,隐式方法就是不明确说明主机要等待设备端,而是设备端不执行完,主机没办法进行,比如内存拷贝函数:
cudaError_t cudaMemcpy(void* dst,const void * src,
size_t count,cudaMemcpyKind kind);
//当核函数启动后的下一条指令就是从设备复制数据回主机端,那么主机端必须要等待设备端计算完成。
对于核函数的声明,我们要注意到:
| 限定符 | 执行 | 调用 | 备注 |
|---|---|---|---|
| global | 设备端执行 | 可以从主机调用也可以从计算能力3以上的设备调用 | 必须有一个void的返回类型 |
| device | 设备端执�行 | 设备端调用 | |
| host | 主机端执行 | 主机调用 | 可以省略 |
有些函数可以同时定义为 device 和 host ,这种函数可以同时被设备和主机端的代码调用,但是要声明成设备端代码,告诉nvcc编译成设备机器码,同时声明主机端设备端函数,告诉编译器,生成两份不同设备的机器码。
Kernel核函数编写有以下限制
-
只能访问设备内存
-
必须有void返回类型
-
不支持可变数量的参数
-
不支持静态变量
-
显示异式行为
写了核函数最重要的是验证正确性,可以使用这样的工具:
void checkResult(float * hostRef,float * gpuRef,const int N)
{
double epsilon=1.0E-8;
for(int i=0;i<N;i++)
{
if(abs(hostRef[i]-gpuRef[i])>epsilon)
{
printf("Results don\'t match!\n");
printf("%f(hostRef[%d] )!= %f(gpuRef[%d])\n",hostRef[i],i,gpuRef[i],i);
return;
}
}
printf("Check result success!\n");
}
CUDA基本都是异步执行的,当错误出现的时候,不一定是哪一条指令触发的,为了防御性编程可以用:
#define CHECK(call)\
{\
const cudaError_t error=call;\
if(error!=cudaSuccess)\
{\
printf("ERROR: %s:%d,",__FILE__,__LINE__);\
printf("code:%d,reason:%s\n",error,cudaGetErrorString(error));\
exit(1);\
}\
}
获得每个函数执行后的返回结果,然后对不成功的信息加以处理,CUDA C 的API每个调用都会返回一个错误代码,在release版本中可以去除这部分,但是开发的时候一定要有。
核函数记时
CPU中计时
在CPU中的计时,我们通常会这么做:
#include <chrono>
int main() {
auto start = std::chrono::steady_clock::now();
// 执行要测试的代码
auto end = std::chrono::steady_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start);
// 输出执行时间
std::cout << "Execution time: " << duration.count() << " milliseconds" << std::endl;
return 0;
}
#include <chrono>
#include <iostream>
#define TIME_IT(func) \
do { \
auto start = std::chrono::steady_clock::now(); \
func; \
auto end = std::chrono::steady_clock::now(); \
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start); \
std::cout << "Execution time: " << duration.count() << " milliseconds" << std::endl; \
} while(0)
void myFunction() {
// 要测试的代码
}
int main() {
TIME_IT(myFunction());
return 0;
}
但对于核函数不能这么测试,在这里我们可以使用另外一种:
#include <sys/time.h>
double cpuSecond()
{
struct timeval tp;
gettimeofday(&tp,NULL);
return((double)tp.tv_sec+(double)tp.tv_usec*1e-6);
}
//gettimeofday是linux下的一个库函数,创建一个cpu计时器,从1970年1月1日0点以来到现在的秒
iStart是cpuSecond返回一个秒数,接着执行核函数,核函数开始执行后马上返回主机线程,所以我们必须要加一个同步函数等待核函数执行完毕,
如果不加这个同步函数,那么测试的时间是从调用核函数到核函数返回给主机线程的时间段,而不是核函数的执行时间.
//timer
double iStart,iElaps;
iStart=cpuSecond();
sumArraysGPU<<<grid,block>>>(a_d,b_d,res_d,nElem);
cudaDeviceSynchronize();
iElaps=cpuSecond()-iStart;

我们可以大概分析下核函数启动到结束的过程:
-
主机线程启动核函数
-
核函数启动成功
-
控制返回主机线程
-
核函数执行完成
-
主机同步函数侦测到核函数执行完
我们要测试的是24的时间,但是用CPU计时方法,只能测试15的时间,所以测试得到的时间偏长。
CUDA nvprof
对可执行文件使用nvprof可以很容易得到结果.
计算的瓶颈
硬件瓶颈:(其实这里还不够好,理论上应该有线程和块对应的benchmark 各个设备的理论极限可以通过其芯片说明计算得到,比如说:
-
Tesla K10 单精度峰值浮点数计算次数:745MHz核心频率 x 2GPU/芯片 x(8个多处理器 x 192个浮点计算单元 x 32 核心/多处理器) x 2 OPS/周期 =4.58 TFLOPS
-
Tesla K10 内存带宽峰值: 2GPU/芯片 x 256 位 x 2500 MHz内存时钟 x 2 DDR/8位/字节 = 320 GB/s
-
指令比:字节 4.58 TFLOPS/320 GB/s =13.6 个指令: 1个字节
设备信息获取

这里面很多参数是我们后面要介绍的,而且每一个都对性能有影响:
-
CUDA驱动版本
-
设备计算能力编号
-
全局内存大小(1.95G,原文有错误,写成MBytes了)
-
GPU主频
-
GPU带宽
-
L2缓存大小
-
纹理维度最大值,不同维度下的
-
层叠纹理维度最大值
-
常量内存大小
-
块内共享内存大小
-
块内寄存器大小
-
线程束大小
-
每个处理器硬件处理的最大线程数
-
每个块处理的最大线程数
-
块的最大尺寸
-
网格的最大尺寸
-
最大连续线性内存
上面这些都是后面要用到的关键参数,这些会严重影响我们的效率。后面会一一说到,不同的设备参数要按照不同的参数来使得程序效率最大化,所以我们必须在程序运行前得到所有我们关心的参数.
基于以上信息我们可以写通用程序时在编译前执行脚本来获取设备信息,然后在编译时固化最优参数,这样程序运行时就不会被查询设备信息的过程浪费资源。 我们可以用两种方式编写通用程序:
-
运行时获取设备信息:
-
编译程序
-
启动程序
-
查询信息,将信息保存到全局变量
-
功能函数通过全局变量判断当前设备信息,优化参数
-
程序运行完毕
-
-
编译时获取设备信息
-
脚本获取设备信息
-
编译程序,根据设备信息调整固化参数到二进制机器码
-
运行程序
-
程序运行完毕
-
至此CUDA的编程模型大概就是这些了,核函数,计时,内存,线程,设备参数,这些足够能写出比CPU块很多的程序了,但是追求更快的我们要深入研究每一个细节
二、深入CUDA
CUDA执行模型概述
对于CUDA首先要把他和SIMD的操作区分开:
SIMD vs SIMT
单指令多数据的执行属于向量机,比如我们有四个数字要加上四个数字,那么我们可以用这种单指令多数据的指令来一次完成本来要做四次的运算。
这种机制的问题就是过于死板,不允许每个分支有不同的操作,所有分支必须同时执行相同的指令,必须执行没有例外。 单指令多线程SIMT就更加灵活了,虽然两者都是将相同指令广播给多个执行单元,但是SIMT的某些线程可以选择不执行,也就是说同一时刻所有线程被分配给相同的指令,SIMD规定所有人必须执行,而SIMT则规定有些人可以根据需要不执行,这样SIMT就保证了线程级别的并行,而SIMD更像是指令级别的并行。 SIMT包括以下SIMD不具有的关键特性:
-
每个线程都有自己的指令地址计数器
-
每个县城都有自己的寄存器状态
-
每个线程可以有一个独立的执行路径
而上面这三个特性在编程模型可用的方式就是给每个线程一个唯一的标号(blckIdx,threadIdx),并且这三个特性保证了各线程之间的独立
线程束执行的本质
网格中包含线程块,线程块被分配到某一个SM上以后,将分为多个线程束,每个线程束一般是32个线程(目前的GPU都是32个线程,但不保证未来还是32个)在一个线程束中,所有线程按照单指令多线程SIMT的方式执行,每一步执行相同的指令,但是处理的数据为私有的数据

线程束的分化
当遇到条件分支的时候,我们应当小心.每个线程都执行所有的if和else部分,当一部分con成立的时候,执行if块内的代码,有一部分线程con不成立,那么他们不可能去执行else,因为分配命令的调度器就一个,所以这些con不成立的线程等待,等到其他人结束了再继续.线程束分化会产生严重的性能下降。条件分支越多,并行性削弱越严重。 注意线程束分化研究的是一个线程束中的线程,不同线�程束中的分支互不影响。

线程束分化导致的性能下降就应该用线程束的方法解决,根本思路是避免同一个线程束内的线程分化.
当一个线程束中所有的线程都执行if或者,都执行else时,不存在性能下降;只有当线程束内有分歧产生分支的时候,性能才会急剧下降。 线程束内的线程是可以被我们控制的,那么我们就把都执行if的线程塞到一个线程束中,或者让一个线程束中的线程都执行if,另外线程都执行else的这种方式可以将效率提高很多。
Reference
详解CUDA的Context、Stream、Warp、SM、SP、Kernel、Block、Grid
https://zhuanlan.zhihu.com/p/266633373
并行计算入门 UIUC ECE408 Lecture 1&2 - 冰点蓝的文章 - 知乎 https://zhuanlan.zhihu.com/p/608744980
并行计算入门 UIUC ECE408 Lecture 3&4 - 冰点蓝的文章 - 知乎 https://zhuanlan.zhihu.com/p/609977231
并行计算入门 UIUC ECE408 Lecture 5&6 - 冰点蓝的文章 - 知乎 https://zhuanlan.zhihu.com/p/614109686
并行计算入门 UIUC ECE408 Lecture 7&8 - 冰点蓝的文章 - 知乎 https://zhuanlan.zhihu.com/p/617296073
GPU CUDA编程中threadIdx, blockIdx, blockDim, gridDim之间的区别与联系
https://blog.csdn.net/TH_NUM/article/details/82983282
Optimizing Parallel Reduction in CUDA - Mark Harris(reduce)